You already know by now that we need to cooperate closely with the OS to make I/O operations as efficient as possible. Operating systems such as Linux, macOS, and Windows provide several ways of performing I/O, both blocking and non-blocking.
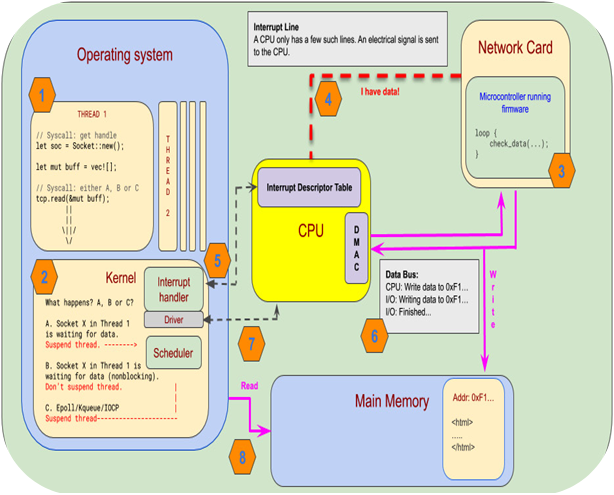
I/O operations need to go through the operating system since they are dependent on resources that our operating system abstracts over. This can be the disk drive, the network card, or other peripherals. Especially in the case of network calls, we’re not only dependent on our own hardware, but we also depend on resources that might reside far away from our own, causing a significant delay.
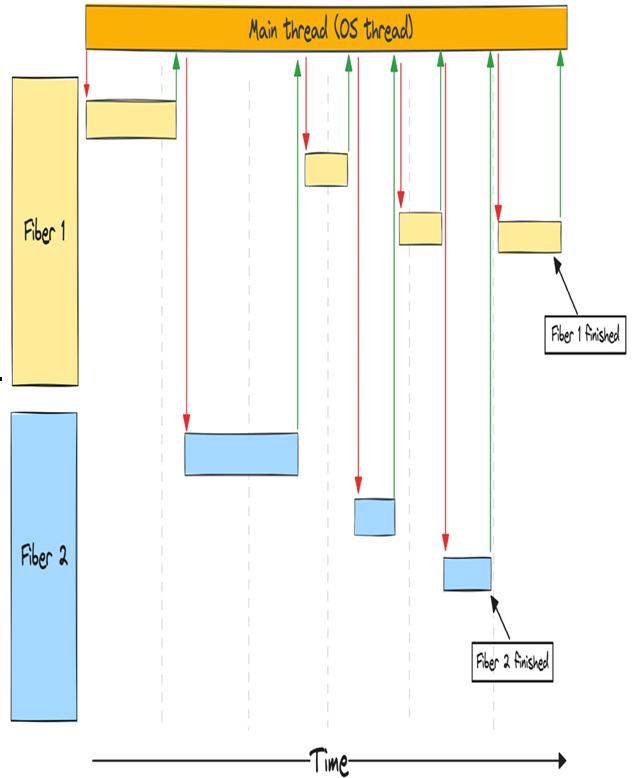
In the previous chapter, we covered different ways to handle asynchronous operations when programming, and while they’re all different, they all have one thing in common: they need control over when and if they should yield to the OS scheduler when making a syscall.
In practice, this means that syscalls that normally would yield to the OS scheduler (blocking calls) needs to be avoided and we need to use non-blocking calls instead. We also need an efficient way to know the status of each call so we know when the task that made the otherwise blocking call is ready to progress. This is the main reason for using an OS-backed event queue in an asynchronous runtime.
We’ll look at three different ways of handling an I/O operation as an example.
Blocking I/O
When we ask the operating system to perform a blocking operation, it will suspend the OS thread that makes the call. It will then store the CPU state it had at the point where we made the call and go on to do other things. When data arrives for us through the network, it will wake up our thread again, restore the CPU state, and let us resume as if nothing has happened.
Blocking operations are the least flexible to use for us as programmers since we yield control to the OS at every call. The big advantage is that our thread gets woken up once the event we’re waiting for is ready so we can continue. If we take the whole system running on the OS into account, it’s a pretty efficient solution since the OS will give threads that have work to do time on the CPU to progress. However, if we narrow the scope to look at our process in isolation, we find that every time we make a blocking call, we put a thread to sleep, even if we still have work that our process could do. This leaves us with the choice of spawning new threads to do work on or just accepting that we have to wait for the blocking call to return. We’ll go a little more into detail about this later.
Non-blocking I/O
Unlike a blocking I/O operation, the OS will not suspend the thread that made an I/O request, but instead give it a handle that the thread can use to ask the operating system if the event is ready or not.
We call the process of querying for status polling.
Non-blocking I/O operations give us as programmers more freedom, but, as usual, that comes with a responsibility. If we poll too often, such as in a loop, we will occupy a lot of CPU time just to ask for an updated status, which is very wasteful. If we poll too infrequently, there will be a significant delay between an event being ready and us doing something about it, thus limiting our throughput.