When you write code that is perfectly synchronous from your perspective, stop for a second and consider how that looks from the operating system perspective.
The operating system might not run your code from start to end at all. It might stop and resume your process many times. The CPU might get interrupted and handle some inputs while you think it’s only focused on your task.
So, synchronous execution is only an illusion. But from the perspective of you as a programmer, it’s not, and that is the important takeaway:
When we talk about concurrency without providing any other context, we are using you as a programmer and your code (your process) as the reference frame. If you start pondering concurrency without keeping this in the back of your head, it will get confusing very fast.
The reason I’m spending so much time on this is that once you realize the importance of having the same definitions and the same reference frame, you’ll start to see that some of the things you hear and learn that might seem contradictory really are not. You’ll just have to consider the reference frame first.
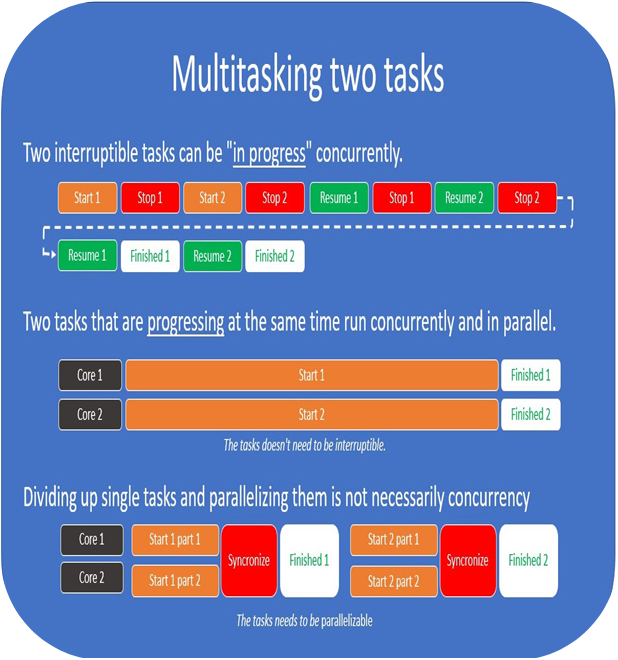
Asynchronous versus concurrent
So, you might wonder why we’re spending all this time talking about multitasking, concurrency, and parallelism, when the book is about asynchronous programming.
The main reason for this is that all these concepts are closely related to each other, and can even have the same (or overlapping) meanings, depending on the context they’re used in.
In an effort to make the definitions as distinct as possible, we’ll define these terms more narrowly than you’d normally see. However, just be aware that we can’t please everyone and we do this for our own sake of making the subject easier to understand. On the other hand, if you fancy heated internet debates, this is a good place to start. Just claim someone else’s definition of concurrent is 100 % wrong or that yours is 100 % correct, and off you go.
For the sake of this book, we’ll stick to this definition: asynchronous programming is the way a programming language or library abstracts over concurrent operations, and how we as users of a language or library use that abstraction to execute tasks concurrently.
The operating system already has an existing abstraction that covers this, called threads. Using OS threads to handle asynchrony is often referred to as multithreaded programming. To avoid confusion, we’ll not refer to using OS threads directly as asynchronous programming, even though it solves the same problem.
Given that asynchronous programming is now scoped to be about abstractions over concurrent or parallel operations in a language or library, it’s also easier to understand that it’s just as relevant on embedded systems without an operating system as it is for programs that target a complex system with an advanced operating system. The definition itself does not imply any specific implementation even though we’ll look at a few popular ones throughout this book.
If this still sounds complicated, I understand. Just sitting and reflecting on concurrency is difficult, but if we try to keep these thoughts in the back of our heads when we work with async code I promise it will get less and less confusing.