The role of the operating system
The operating system (OS) stands in the center of everything we do as programmers (well, unless you’re writing an operating system or working in the embedded realm), so there is no way for us to discuss any kind of fundamentals in programming without talking about operating systems in a bit of detail.
Concurrency from the operating system’s perspective
This ties into what I talked about earlier when I said that concurrency needs to be talked about within a reference frame, and I explained that the OS might stop and start your process at any time.
What we call synchronous code is, in most cases, code that appears synchronous to us as programmers. Neither the OS nor the CPU lives in a fully synchronous world.
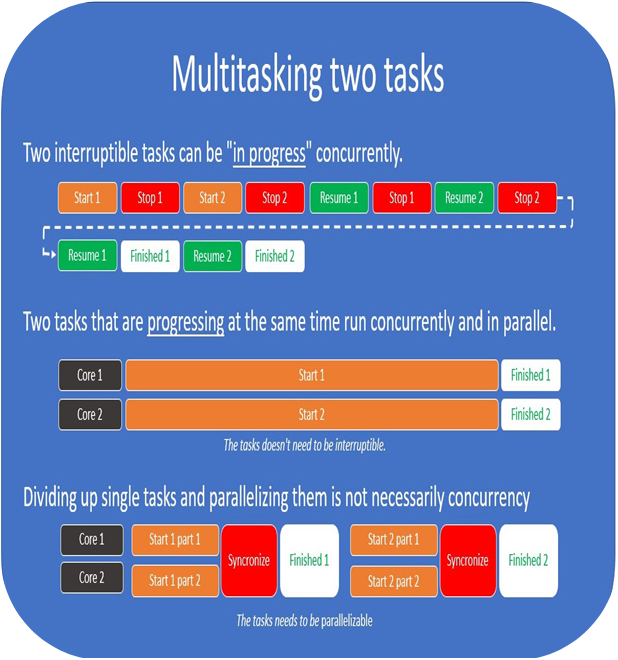
Operating systems use preemptive multitasking and as long as the operating system you’re running is preemptively scheduling processes, you won’t have a guarantee that your code runs instruction by instruction without interruption.
The operating system will make sure that all important processes get some time from the CPU to make progress.
Note
This is not as simple when we’re talking about modern machines with 4, 6, 8, or 12 physical cores, since you might actually execute code on one of the CPUs uninterrupted if the system is under very little load. The important part here is that you can’t know for sure and there is no guarantee that your code will be left to run uninterrupted.
Teaming up with the operating system
When you make a web request, you’re not asking the CPU or the network card to do something for you – you’re asking the operating system to talk to the network card for you.
There is no way for you as a programmer to make your system optimally efficient without playing to the strengths of the operating system. You basically don’t have access to the hardware directly. You must remember that the operating system is an abstraction over the hardware.
However, this also means that to understand everything from the ground up, you’ll also need to know how your operating system handles these tasks.To be able to work with the operating system, you’ll need to know how you can communicate with it, and that’s exactly what we’re going to go through next.